性能定位过程
Last updated on 3 months ago
前言
近期做一些性能调优的事,很折腾人,麒麟的OS 和 centos OS 读写性能差距很大,尤其是大块读写,相同物理环境,相同的产品,OS不同,差距为什么会如此之大,我也知道 OS 不同,内核版本不同,内核的参数也不同,性能肯定会受影响,但内核的参数我也就知道几个,只好摸石头过河,边学边干了,这过程中学到了很多新的东西,这里记录下过程
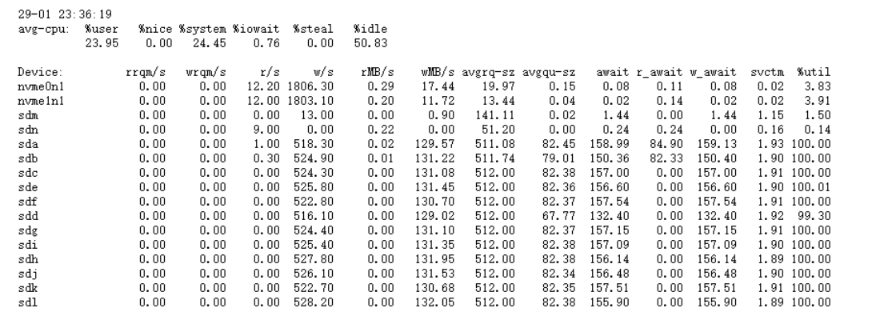
怀疑是到磁盘的瓶颈了,于是压测时 用 iostat 看,util 和 w_await 都不高
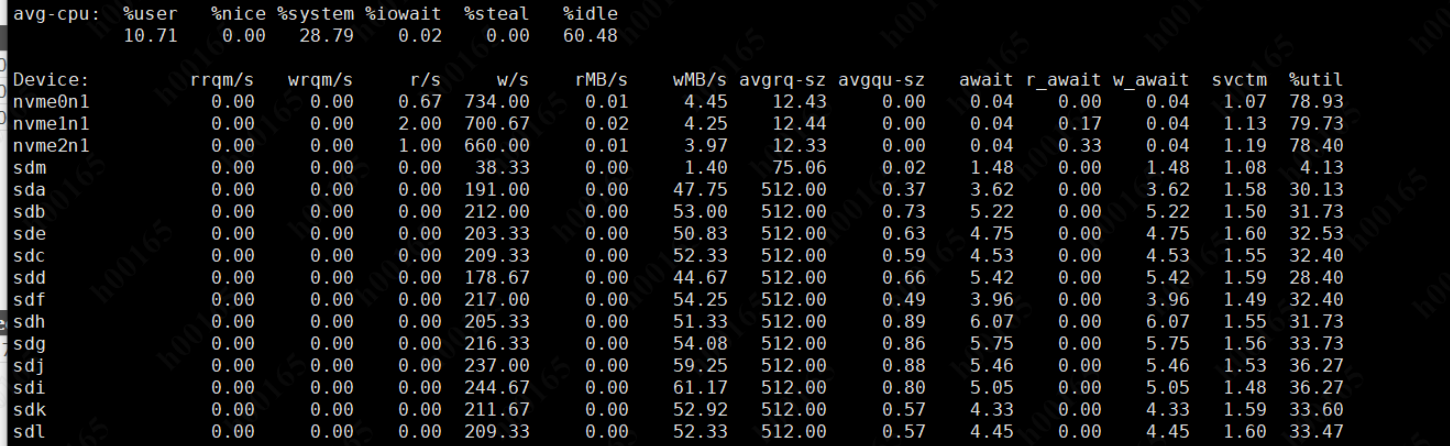
于是找到以前 centos 的压测时的 iostat ,很明显 看出 centos 上的磁盘性能 已经发挥到了极致! 相对 现在麒麟都没什么压力
排除磁盘瓶颈,于时我又想到会不会时 OSD出了问题? 借助 ceph 的探测工具, 可以看到osd上每个 op 的平均处理时间,一个op要38ms?这就有点离谱了,不至于吧?
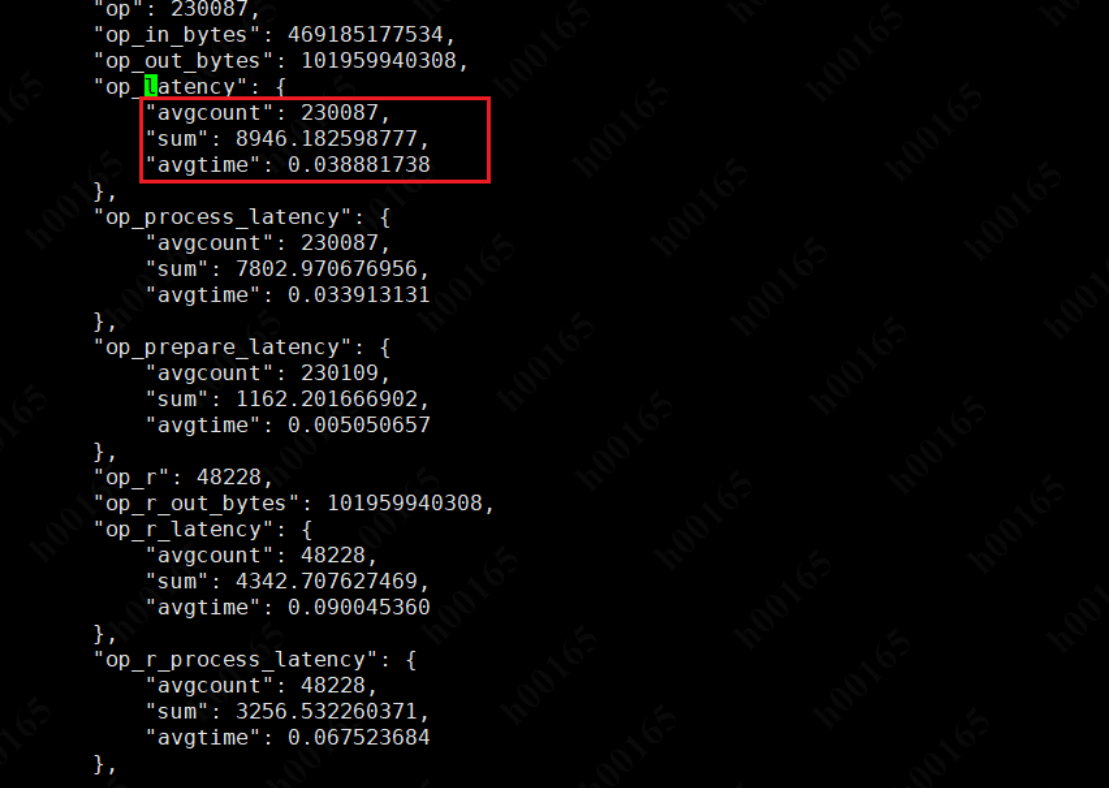
继续深入看下,这每个op 时间 耗费在那里? 借助 ceph 的工具可以知道近期的op 各个处理的环节;由于 ceph 的写时强一致性,所以要等每个副本都reply 了才算完成一个op; 这之间的16ms ,是耗费在那?是数据包发送时间长 还是写时间长? 可是上面看磁盘都没什么压力,目前怀疑 是网络问题
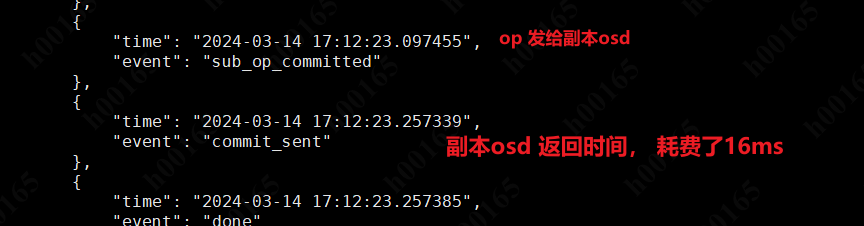
先用 iperf3 打流看下网卡带宽,这里用iftop 来检测网卡带宽,测试时发现 带宽没达到预期;25G的网卡带宽起码要有 20Gbit 上下才对,差了几个G?是什么意思?
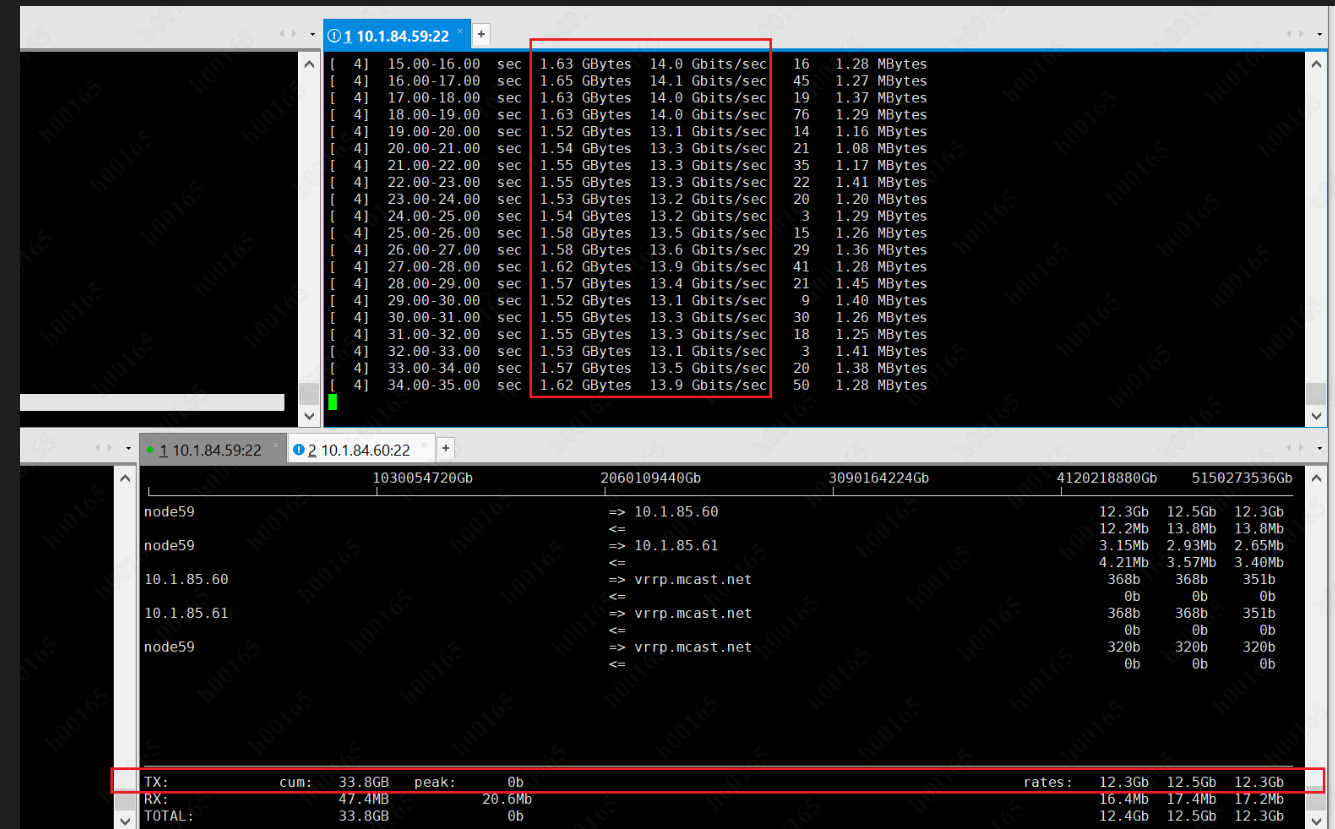
更加怀疑是网络问题,于是用 tcpdump 抓包(现学先用),用wireshard 分析tcp 时序图,发现8M io 业务下,时序图并不是平滑的,y 轴是tcp 的syn 号,x轴是 时间; 这也说明网络连接是很不稳定的(重传,拥塞等),一个包等待了时间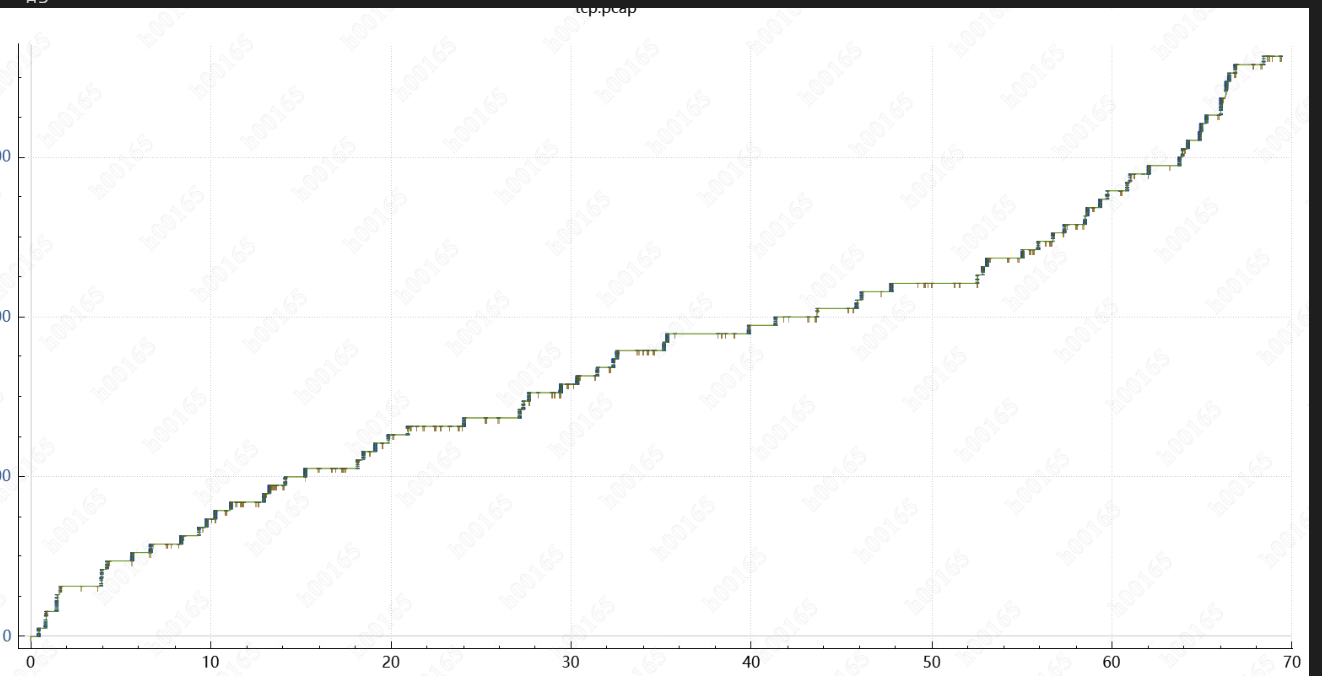
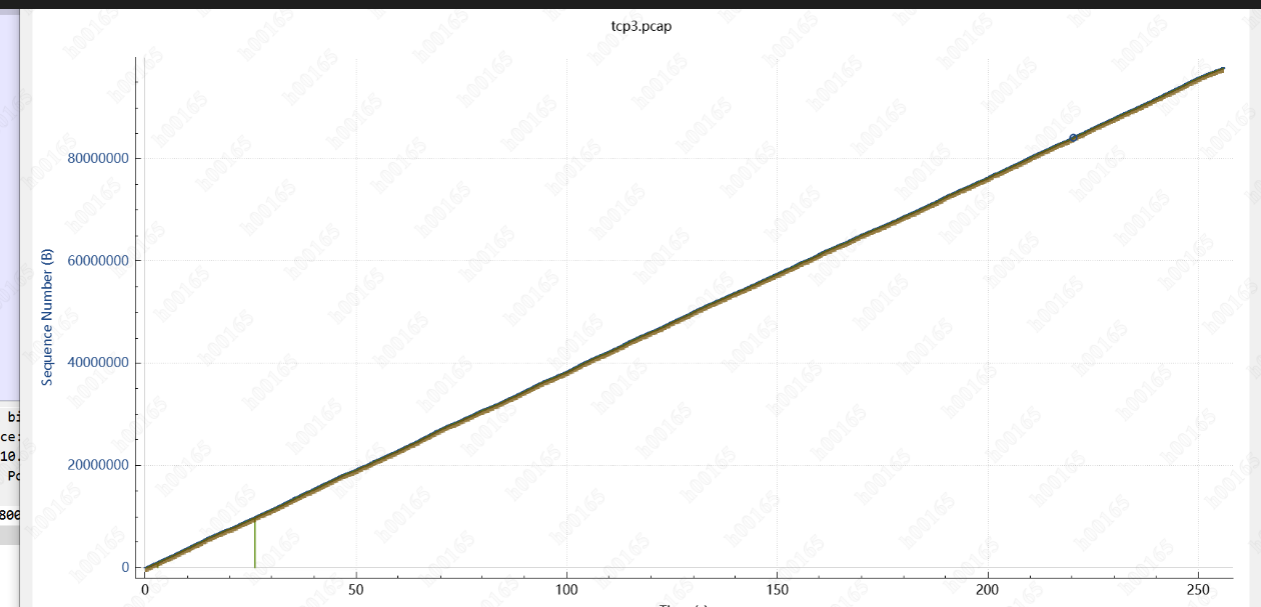
用 1M的对比了下,时序图很丝滑,8M的IO和1M的IO 对网络协议栈 影响那么大? (以后再研究)
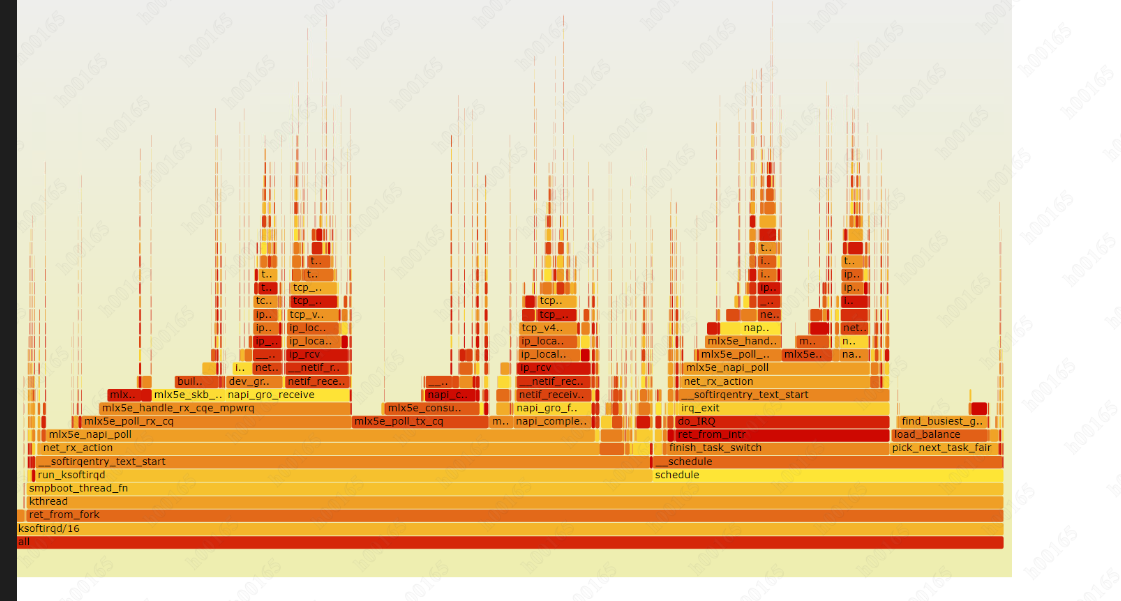
借这个机会,perf 生成火焰图看 网络协议栈调用的函数(看不懂,但 ip_rcv 函数很红,说明这个函数消耗cpu资源多)