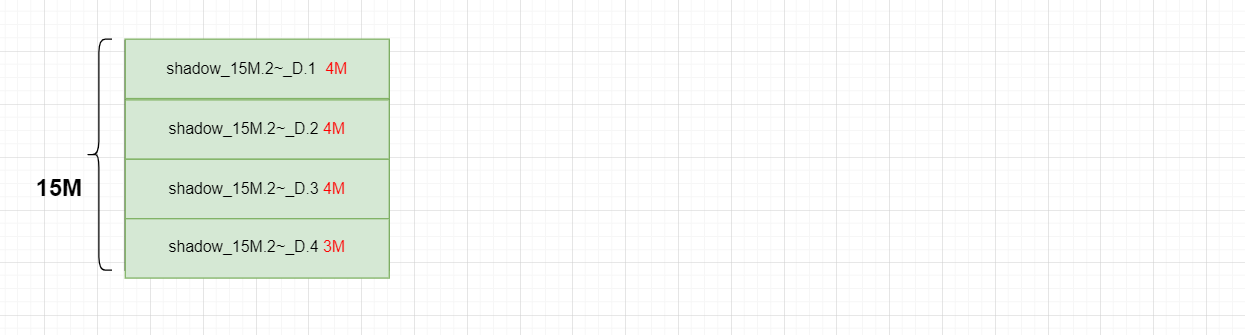Last updated on a year ago
前言 本文主题: 当我们用 s3cmd 上传文件是,rgw是如何处理的
对于s3cmd(s3 api) 的每个请求操作,再rgw 中都有对应的 handle op 来处理RGWPutObj::execute()
在处理之前的流程基本都是通用的,即 解析请求 -> 验证请求 -> 生成对应hanle (流程多,单独一篇文章介绍)
对于每个 op主要处理流程都分为这个三个函数
主要数据结构以及类关系 rgw 对象分布
对象上传的内容存放在 rgw.data池中 对象内容 上传 5M 的数据
rgw 会把数据切割成4M odj
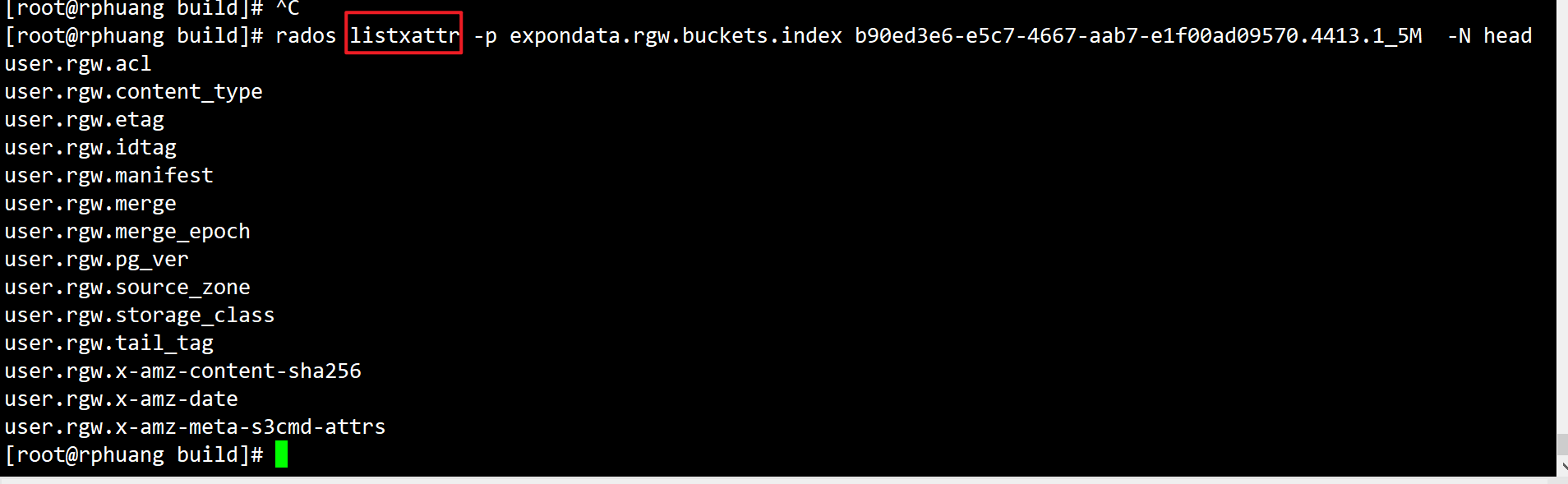
index pool : 存放 rgw 对象的索引信息
.dir.[桶id].[shard_num] : 这个是 会存放该桶所包含的索引(上传对象的文件名字)
[桶id]_[对象名字] : 这里以 xattr 形式存放着 上传对象的元数据
上传的方式又可以分为两种(data 池中存放的方式不同)
分段上传 : 上传文件大小超过15M 后自动自动
这里规则是: RGW对象由一个首部RADOS对象和多个分段对象组成,每个分段对象又由multipart RADOS对象和分片RADOS对象组成
整体上传 (小于15M):会以4M 的粒度写入rados
关键流程 RGWPutObj::pre_exec() 1 2 3 4 5 6 7 void rgw_bucket_object_pre_exec (struct req_state *s) if (s->expect_cont)dump_continue (s);dump_bucket_from_state (s);
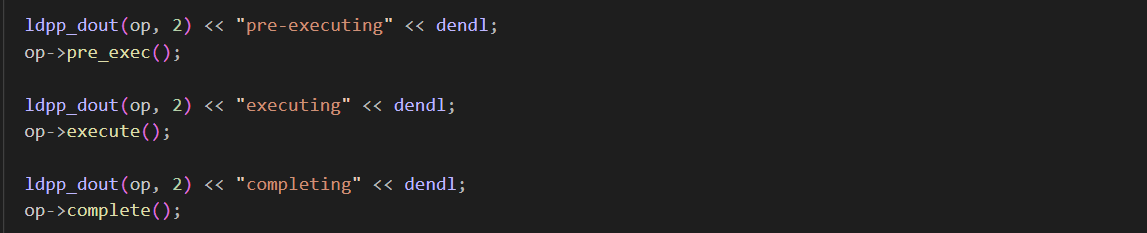
RGWPutObj::execute() 该函数中 前面做一些 校验,后面根据不同上传方式来 初始化不同的功能类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 void RGWPutObj::execute () if (s->object.empty ()) {return ;if (!s->bucket_exists) {return ;if (supplied_md5_b64) {if (!chunked_upload) {check_quota (s->bucket_owner.get_id (), s->bucket,if (supplied_etag) {strncpy (supplied_md5, supplied_etag, sizeof (supplied_md5) - 1 );sizeof (supplied_md5) - 1 ] = '\0' ;const bool multipart = !multipart_upload_id.empty ();rgw::AioThrottle aio (store->ctx()->_conf->rgw_put_obj_min_window_size) ;using namespace rgw::putobj;constexpr auto max_processor_size = std::max ({sizeof (MultipartObjectProcessor),sizeof (AtomicObjectProcessor),sizeof (AppendObjectProcessor)});if (multipart) {RGWMPObj mp (s->object.name, multipart_upload_id) ;get_multipart_info (store, s, mp.get_meta (), nullptr , nullptr , &upload_info);ldpp_dout (this , 20 ) << "dest_placement for part=" << upload_info.dest_placement << dendl;emplace <MultipartObjectProcessor>(get_id (), obj_ctx, obj,if (s->bucket_info.versioning_enabled ()) {if (!version_id.empty ()) {set_instance (version_id);else {gen_rand_obj_instance_name (&obj);ldpp_dout (this , 20 ) << "other" << "other" << dendl;amend_placement_rule (s->dest_placement);emplace <AtomicObjectProcessor>(get_id (), obj_ctx, obj, olh_epoch, s->req_id);
分段上传 :
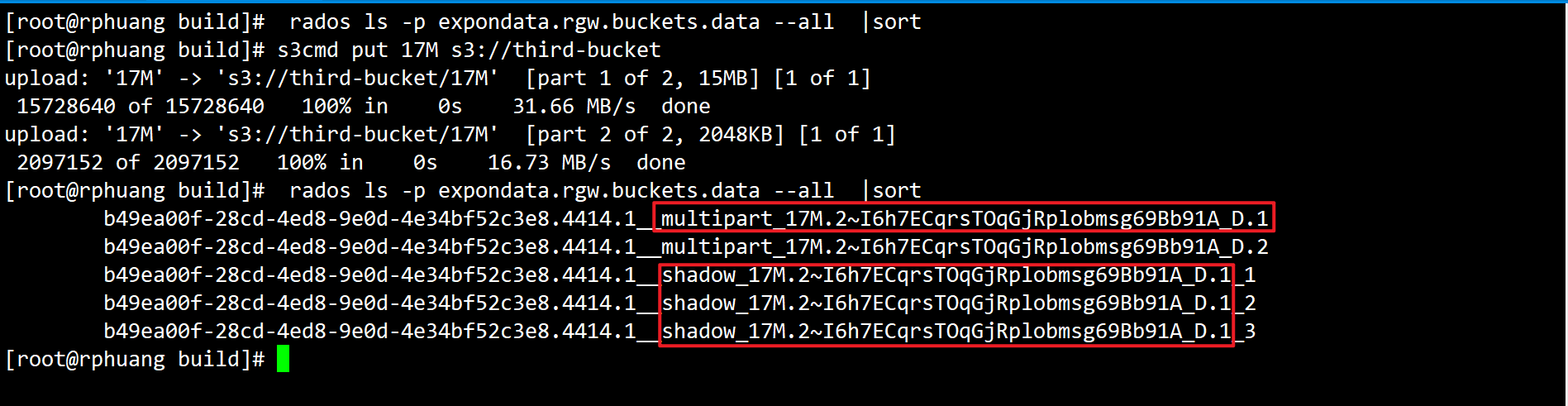
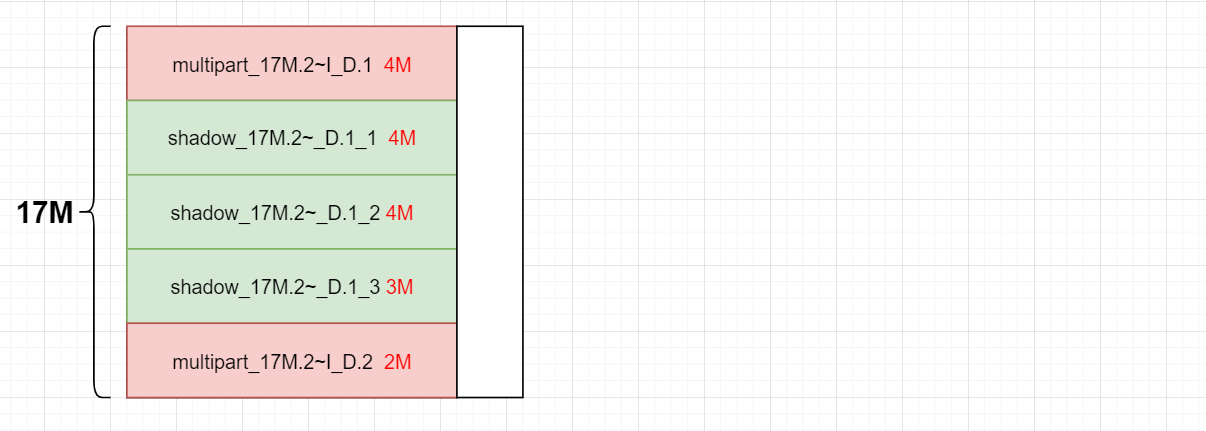
对于一个大的RGW Object,会被切割成多个独立的RGW Object上传,称为multipart。multipar的优势是断点续传。s3接口默认切割大小为15MB(这个数值可以修改)
multipart: multipart分段首对象,
{bucket_id}_multipart{prefix}.{multipart_id},其中multipart_id根据manifest计算;
shadow : 从属于multipart的分段对象,{bucket_id}_shadow {prefix}.{multipart_id}_{shadow_id},shadow_id:根据manifest.rule.part_size及 manifest.rule.stripe_max_size计算。
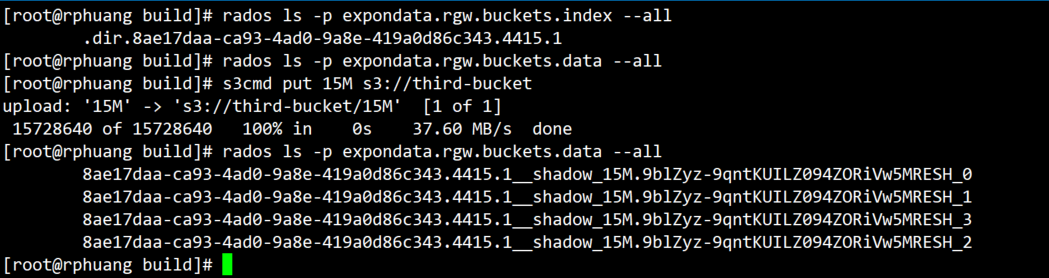
整体上传: 相关概念 小于 4M : 数据存放在 .rgw.buckets.data 池中,会生成一个rados 对象(默认4M)
大于4M : 文件会分割成 4M大小rados
c2c8dcbe-1203-4be1-b58b-5dc19a95fca9.4194.1__shadow_file.ECv7yKnV7oudlcFrIWHTsJ5QrYBhNdd_0
具体流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 if (s->bucket_info.versioning_enabled ()) {if (!version_id.empty ()) {set_instance (version_id);else {gen_rand_obj_instance_name (&obj);ldpp_dout (this , 20 ) << "atomic" << "other" << dendl;amend_placement_rule (s->dest_placement);emplace <AtomicObjectProcessor>(get_id (), obj_ctx, obj, olh_epoch, s->req_id);prepare ();
AtomicObjectProcessor::prepare() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 int int AtomicObjectProcessor::prepare () uint64_t max_head_chunk_size;uint64_t head_max_size;uint64_t chunk_size = 0 ;uint64_t alignment;if (!store->get_obj_data_pool (bucket_info.placement_rule, head_obj, &head_pool)) {ldout (store->ctx (), 0 ) << "fail to get head pool " << head_obj << ",rule=" << bucket_info.placement_rule << dendl;return -EIO;int r = store->get_max_chunk_size (head_pool, &max_head_chunk_size, &alignment);if (r < 0 ) {return r;set_trivial_rule (head_max_size, stripe_size);char buf[33 ];gen_rand_alphanumeric (store->ctx (), buf, sizeof (buf) - 1 );"." ;append (buf);append ("_" );set_prefix ( head_obj.key.name + oid_prefix);create_begin (store->ctx (), &manifest,if (r < 0 ) {ldout (store->ctx (), 0 ) << "fail to create manifest " << head_obj << ",ret=" << r << dendl;return r;get_cur_obj (store);set_stripe_obj (stripe_obj);if (r < 0 ) {ldout (store->ctx (), 0 ) << "fail to set_stripe_obj " << head_obj << ",ret=" << r << dendl;return r;set_head_chunk_size (head_max_size);ChunkProcessor (&writer, chunk_size);StripeProcessor (&chunk, this , head_max_size);return 0 ;
循环读数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 do {if (fst > lst)break ;if (copy_source.empty ()) {get_data (data);else {uint64_t cur_lst = min (fst + s->cct->_conf->rgw_max_chunk_size - 1 , lst);get_data (fst, cur_lst, data);if (op_ret < 0 )return ;length ();if (len < 0 ) {ldpp_dout (this , 20 ) << "get_data() returned ret=" << op_ret << dendl;return ;else if (len == 0 ) {break ;if (need_calc_md5) {Update ((const unsigned char *)data.c_str (), data.length ());update (data);process (std::move (data), ofs);if (op_ret < 0 ) {ldpp_dout (this , 20 ) << "processor->process() returned ret=" return ;while (len > 0 );
filter->process(std::move(data), ofs); —-> HeadObjectProcessor::process
收到数据 现在这处理(关键处理函数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 int HeadObjectProcessor::process (bufferlist&& data, uint64_t logical_offset) const bool flush = (data.length () == 0 );if (data_offset < head_chunk_size || data_offset == 0 ) {if (flush) {ldout (store->ctx (), 20 ) << "process flush offset:" << data_offset << " data len:" << head_data.length () <<dendl;return process_first_chunk (std::move (head_data), &processor); auto remaining = head_chunk_size - data_offset;auto count = std::min <uint64_t >(data.length (), remaining);splice (0 , count, &head_data);if (data_offset == head_chunk_size) {ceph_assert (head_data.length () == head_chunk_size);ldout (store->ctx (), 20 ) << "process first chunk, offset:" << data_offset << " data len:" << head_data.length () <<dendl;int r = process_first_chunk (std::move (head_data), &processor);if (r < 0 ) {return r;ldout (store->ctx (), 20 ) << " !!! " <<dendl;if (data.length () == 0 ) { return 0 ;ceph_assert (processor); auto write_offset = data_offset;length ();ldout (store->ctx (), 20 ) << "process data, write offset:" << write_offset << " data len:" << data.length () <<dendl;return processor->process (std::move (data), write_offset);
HeadObjectProcessor::process 主要作用是 把首个4M的对象单独处理,此外将4M以后的 数据交给下一个 process (StripeProcessor::process)
4M 以后写数据流程 是 StripeProcessor::process -> ChunkProcessor::process() -> RadosWriter::process()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 int StripeProcessor::process (bufferlist&& data, uint64_t offset) ceph_assert (offset >= bounds.first);const bool flush = (data.length () == 0 );if (flush) {return Pipe::process ({}, offset - bounds.first);auto max = bounds.second - offset;while (data.length () > max) {if (max > 0 ) {splice (0 , max, &bl);int r = Pipe::process (std::move (bl), offset - bounds.first);if (r < 0 ) {return r;int r = Pipe::process ({}, offset - bounds.first); if (r < 0 ) {return r;uint64_t stripe_size;next (offset, &stripe_size);if (r < 0 ) {return r;ceph_assert (stripe_size > 0 );if (data.length () == 0 ) { return 0 ;return Pipe::process (std::move (data), offset - bounds.first);
接下来 以上传一个 10M 大小的文件例子,结合代码数据是怎么切割下发到 rados的
10M 的属于整体上传,会被切割成3份(在 上面所提到的do… while 中每次取 4M) ,分别是 4M 4M 2M
第一个4M 1 2 3 4 5 6 7 8 9 10 process (std::move (data), ofs); process (bufferlist&& data, uint64_t logical_offset) process_first_chunk (std::move (head_data), &processor);process (std::move (data), 0 ) write_full (data)
第二个 4M 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 process (std::move (data), ofs); process (bufferlist&& data, uint64_t logical_offset) process (std::move (data), write_offset); const bool flush = (data.length () == 0 ); auto max = bounds.second - offset; while (data.length () > max) {..} process ({}, offset - bounds.first)next (offset, &stripe_size); process (std::move (data), offset - bounds.first); process (bufferlist&& data, uint64_t offset) int64_t position = offset - chunk.length (); length () == 0 ); claim_append (data); while (chunk.length () >= chunk_size) splice (0 , chunk_size, &bl); int r = Pipe::process (std::move (bl), position); write (offset, data)
剩下的数据 2M 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 filter->process (std::move (data), ofs); process (bufferlist&& data, uint64_t logical_offset) process (std::move (data), write_offset); const bool flush = (data.length () == 0 ); auto max = bounds.second - offset; while (data.length () > max) {..} process ({}, offset - bounds.first)next (offset, &stripe_size); process (std::move (data), offset - bounds.first); process (bufferlist&& data, uint64_t offset) int64_t position = offset - chunk.length (); length () == 0 ); claim_append (data); while (chunk.length () >= chunk_size) splice (0 , chunk_size, &bl);int r = Pipe::process (std::move (bl), position); write (offset, data)process ({}, ofs); process (bufferlist&& data, uint64_t logical_offset) process (std::move (data), write_offset); const bool flush = (data.length () == 0 ); process ({}, offset - bounds.first); process ({},2 M) const bool flush = (data.length () == 0 ); if (chunk.length () > 0 ) process (std::move (chunk), position); write_full (data);
整体上传比较特殊的是 第一个 part 和 最后一段数据 (do….while 读取完才刷新)
接下介绍对象 元数据是如何存的(head )



 主要分为两种:
主要分为两种: