osd 心跳(深入理解)
Last updated on a year ago
使用场景
在分布式系统中有很多节点,节点数量多了,各种异常就会经常发生,如:宕机、磁盘损坏、网络故障等;如果集群的某个节点出现什么故障是难以知道的;还有就是监测各个节点的健康状况,快速定位集群中的异常节点。
心跳机制是什么
通俗解释: 客户端每隔 N秒发送心跳数据包给服务端,正常来说在M秒内,服务端会回复客户端消息,若是 服务端大于M秒内没回复,则客户端会认为是出现心跳超时的异常,客户端会进一步对超时异常做处理。
以上只是一个大概的流程,在发送心跳的前后都需要做很多处理,对于收到的心跳包可能有很多种类型,需要分不同情况处理(后续会说明);
在ceph 中 能解决了什么问题
osd之间互相检测健康情况,以便及时发现故障节点进入相应的故障处理流程,此外可以分担mon检测的压力
检测到 public和cluster 网络异常
发送心跳的前提是自身状态的是正常的,所以自身也会先检测:
内部操作是否超时(内部线程的操作)
自身osdmap不与集群的一致
自身osd状态 检测
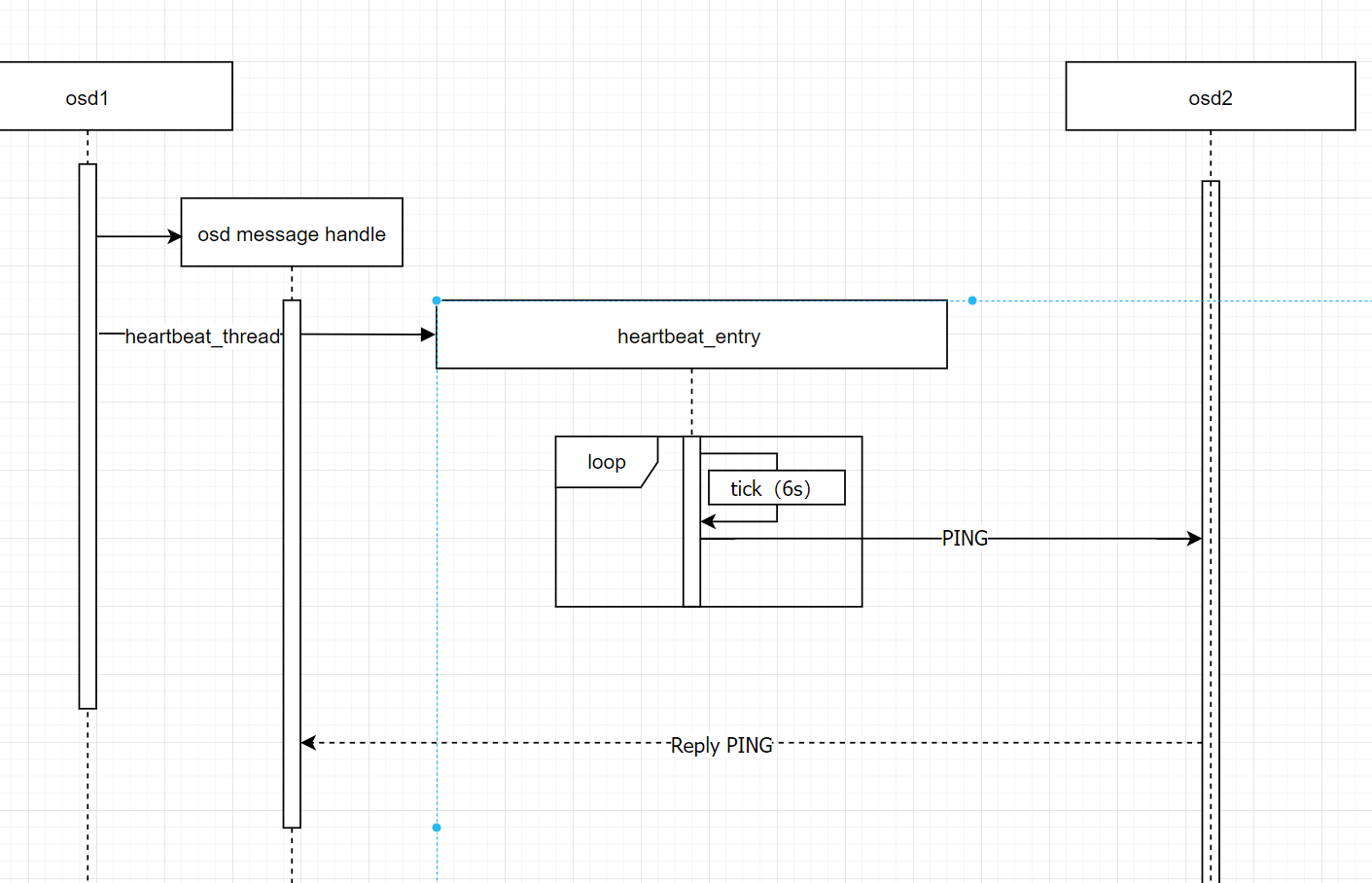
osd 和osd 之间心跳
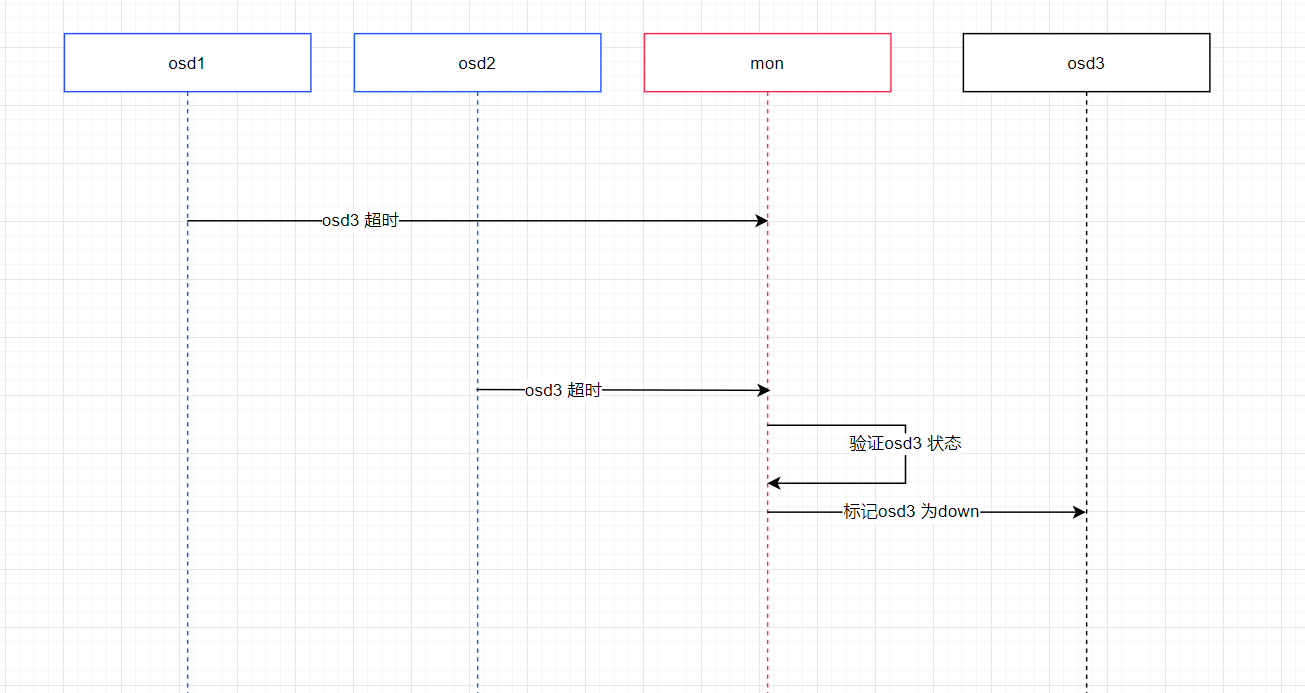
mon和osd 之间
- osd 会向 mon上报 超时的osd给mon,mon会根据 osd超时的上报数来决策 该超时的osd 状态
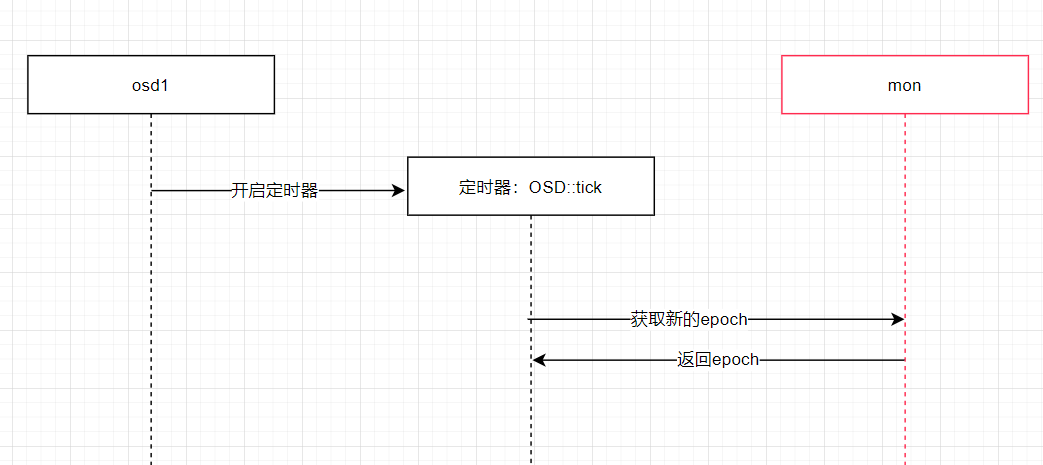
- osd 会每隔 osd_mon_heartbeat_interval 时间(30s)向mon获取最新的 epoch(Monitors 、 OSD 和 PG上的每一次状态变更的都会递增epoch数值) ,这个操作在一个定时器内进行
以下是心跳模块实现细节
osd 是如何选择发送对象
在ceph 中 ,osd并没有广播式的向集群内所有osd发送心跳,因为这样会有心跳风暴对集群造成比较大的压力;osd每次发送心跳时发送的数量为 osd_heartbeat_min_peers(默认为10),这10个发送对象(peer osd) 并不是直接随机选取,而是有选取的规则,选取的 osd会保存在 heartbeat_peers 中; 以下有三种场景下会触发 刷新 heartbeat_peers 的函数
触发更新peer osd有两种方式 (本质上是更新标志位):
- osd 刚启动时
- 距离上一次更新peer osd时间超时限定时间
可以触发的场景:
- 定时器内定期触发
- handle_pg
- handle_map
选取的规则(原则上尽可能选取到指定数量的osd):
- 在PG副本所在OSD的集合中选取 [可选]
- 选取相邻的osd (eg: 当前osd id为5,则会尝试获取 6或者 4 ) [必选]
- 基于报错处理的原则: 需要来自至少两个不同的故障域的osd;所以会在指定的故障域下随机找两个osd;**[必选]**
- 每次发送的对象数量都有所限定,若是大于指定数量则会从 [可选] 集合中剔除掉osd;而太少则会从相邻的osd中再次选取
问题:heartbeat_peer 会自动清掉吗?什么场景会 reset?
- 会自动清楚掉但有条件;为了保证 heartbeat_peer 里面没有 “常驻” osd; 距离上一次更新peer osd时间超过限定时间时,会尝试去清除 heartbeat_peer 中的osd,其条件是在过去的十分钟内都没有对该osd发送过心跳,则这种条件下则会清除;因为10分钟都没更新很有可能这个osd已经down掉了;还有一种情况时 osd 主动shutdown时候,会全部清除掉(释放内存)
问题:选取 peer osd时为什么要通过好几种方式来选择,直接在集群内随机选osd可以吗? 会不会出现个别osd 一直没有选到的情况??
不能直接的随机选;心跳发送并不是广播式的,每次发送的数量是有限定的(避免集群压力过大);在数量一定的情况下首先需要保证检测结果即准确又要快速
【必要】从所在节点中选osd,这样检测本身节点的一个健康状况 (至少两个,后续发现数量不够会继续获取)
【必要】方便mon快速决策,满足报错处理的原则,随机选两个不同的故障域的osd (至多两个)
【补充】在PG副本所在OSD的集合中选取 (数量过多则从这里剔除)
osd发送心跳实现
osd 会单独起一个线程来发送心跳,每隔6s发送一次(官方文档是这么说),但实际操作中是小于6的随机秒数,因为固定数值可能造成网络拥塞;然后遍历 一组osd,逐个发送心跳,发送的时候会先算好超时期限并保存起来,方便检测心跳超时;对于发送的内容是一个MOSDPing类的实例 ;对于集群内只有一个osd的情况每隔 osd_mon_heartbeat_interval 时间会更新osdmap。
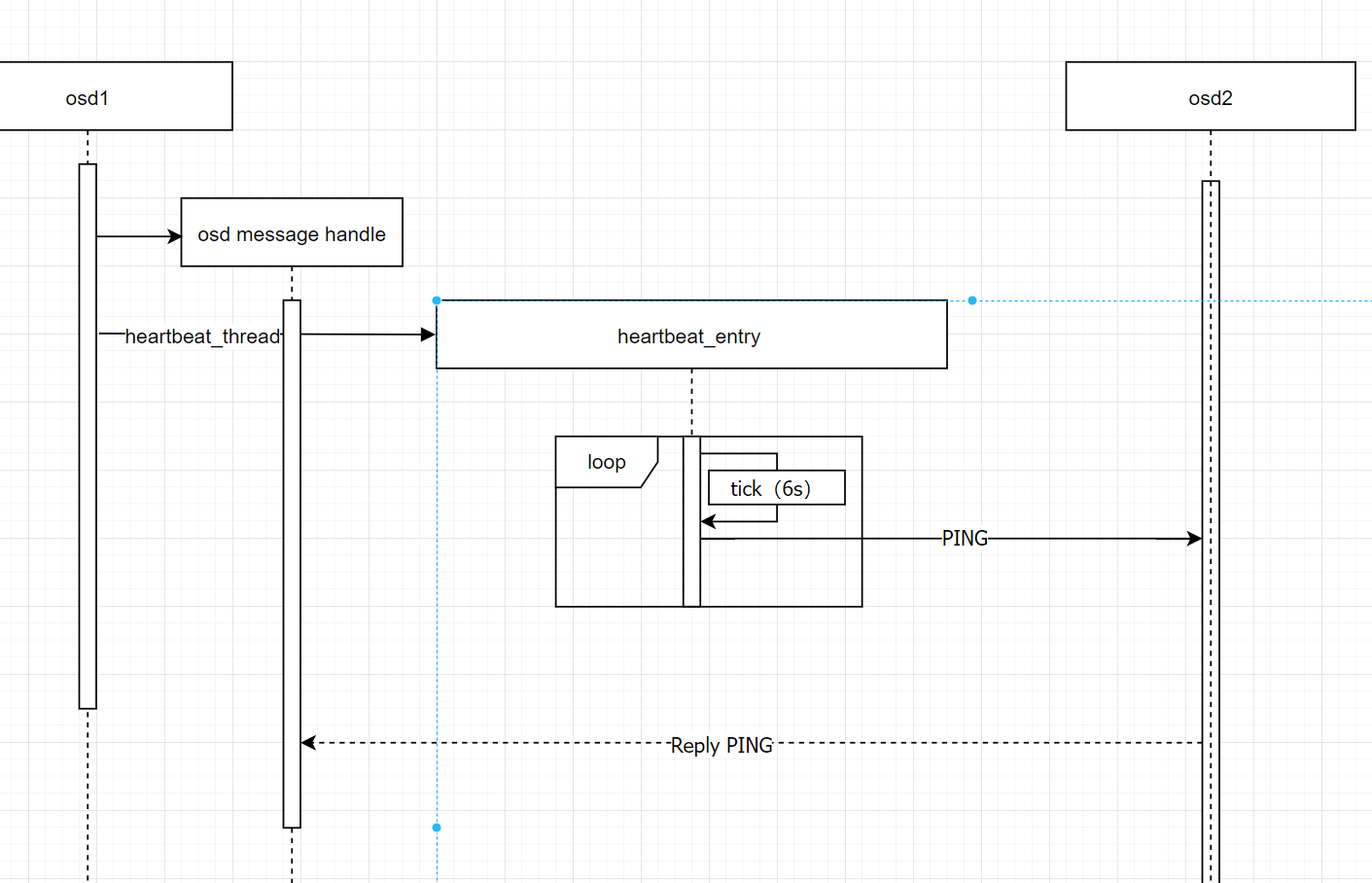
简要描述 :对于osd之间心跳传输,ceph使用了一个单独的线程来做处理,每隔6s向随机选取的osd发送 PING类型的心跳包;正常情况下osd 会在 osd_heartbeat_grace 时间内收到相应osd的 PING_REPLY 类型心跳回复,对于处理osd 的回复ceph 也是注册了message 回调函数专门来处理;若没在指定时间内收到,会将超时回复的osd上报给mon,交给mon来决策该超时osd的状态;
实现细节:
发送前的准备
- 获取 发送对象(peer osd)
- 根据发送对象(osd 的id)找到相应的ping记录,上次更新ping记录的时间和现在相隔超过一个钟(osd_mon_heartbeat_stat_stale 可设置),则需要清空osd的ping记录;
- 检测 osd 容量使用情况
- 计算并记录出此次心跳 回复的截止期限,以及记录发送心跳的时间点 (截止时间必须要,再检测超时的时候有用到)
如何发送
- 构造并发送PING类型 心跳包
特殊处理
- 没有发送对象(集群中可以只有一个osd): 在自身状态正常下(active)每隔 osd_mon_heartbeat_interval时间 向mon 订阅更新osdmap
问题: 心跳线程中间隔时间发送是怎么实现的?sleep?定时器?需要考虑线程同步问题吗?
这里是使用了互斥锁和条件变量实现,间隔时间内,线程是休眠状态(此时会释放锁),达到间隔时间后会唤醒线程; 线程执行过程过程中 有heartbeat_lock 进行保护;
问题: 心跳间隔时间可以修改吗? 时间大小对集群的影响是?
间隔时间可以 由于参数 osd heartbeat interval 设置,默认为6s,但实际上逻辑上实现是基于这个参数生成的随机值,发送的频率的高低会影响集群的性能,对于间隔时间的设置,设置的太短了,有可能会因为当前网络阻塞导致误判;设置的太长,会导致判断“迟缓”,固定的间隔时间也不是是权宜之计,索性就取一定时间内的随机值,一来可以使得发送的频率不会一直都是最高的,;二来随机的发送心跳,对检测结果正确性更有保障;
问题: 心跳线程有没有可能被内部 kill掉呢?
心跳线程的根据一个标志位来判断是否要继续执行, 从代码上看,在osd shutdown的时候会;
osd是如何检测超时的
概述: 检测心跳回复超时也是在一个定时器中,具体操作是遍历 osd已经发送的心跳的对象(peer osd),根据osd 找到当时算好超时期限,并和现在时间做比较,如果小于已经是超时了,代码实现中只会挑出小于当前时间的记录做处理;对于超时的osd会添加到failure_queue里,接下来统一发给mon;
osd 是何如上报给mon的
触发条件
上报mon也是在一个定时器里(同检测超时一个定时器),当前osd状态有变更的时候或者间隔时间大于osd_mon_report_interval 时就会触发上报mon
实现流程
遍历超时检测收集到的超时osd,然后构造 MOSDFailure类,发送给mon
问题 :failure_queue 和 failure_pending 逻辑是怎么处理的?
failure_queue 里保存了报错的osd,failure_pending 保存的是已经上报mon的osd(防止重复上报);假如 failure_queue里面有osd.1的report,此时会验证failure_pending 里面有无osd.1 的记录,没有则会上报,并将osd保存到failure_pending中,若是failure_pending 有纪录,则不会上报,这样做可以避免重复上报;
failure_queue 是上报一次就清除一个(不管是否上报成功)
问题: MOSDFailure 有几种类型,mon是怎么处理的?
- FLAG_ALIVE: 当检测到异常的osd并上报后,后续又发现该异常的osd又正常了,需要重新告知mon,此时就需要FLAG_ALIVE 类型的 MOSDFailure
- FLAG_FAILED: 上报 心跳超时 的异常osd时,默认使用 FLAG_FAILED
- FLAG_IMMEDIATE: 并不是超时引起的异常,mon直接标记为dowm
osd处理 心跳消息
其他osd发来的 心跳包
心跳通知(PING): 其他osd发来的 心跳检测
回复前准备
- 检测内部子系统健康(操作超时)
构建并发送 PING_REPLY 包
- 心跳回复的构造
- 构造 MOSDPing::PING_REPLY 类型的心跳包
- 心跳回复包的大小限定,构造的时候可以指定包大小的最小值,没有满足会自动填充,这样做是在保证心跳包完整下,节省空间;
- 心跳回复的构造
回复后的操作
保存/更新 发送方的epoch(从发来的消息中获取)
在自身osd状态为up下,验证当前osd的epoch 和发送方的epoch是否一致(原则是向新的靠拢)
- 当前的epoch比发送方的大,会share给发送方
- 内部更新发送方的epoch
从自身的osdmap中验证发送方的状态
- 发送方不存在,会发送 YOU_DIED 类型的心跳包
问题: 回复心跳包前 检测内部子系统健康目的是什么?有什么设计细节?
对于内部子系统(subsystems)健康机制都是由一个HeartbeatMap 类负责,每个子系统对应一个结构体,这些子系统初始化时将该结构体加入 HeartbeatMap 类中一个链表里以方便后续访问;每个结构体内部会定期更新 grace (容忍时间期限);当我们需要验证内部子系统健康状态时,只需遍历HeartbeatMap中的 链表用以访问每个子系统,以现在的时间去逐个比较子系统 的grace,若是大于grace 则说明是超时了,此外这个步骤也会顺便验证 子系统的自杀时间,若超时也会杀掉子系统。
结合代码看,这些结构体 多数是由线程work注册的,work一些操作可能会超时…..
问题: 心跳回复包的构造有个参数是指定 心跳回复包的最小大小,为什么要设计最小大小呢?
默认值是2000,在处理解包信息时候,不足会自动填充,
至于设计的大小….
问题: 回复才来来验证epoch,以及验证对方状态,这两者先后有什么区别呢?
不管对方状况如何,都应该回复(总之收到了包就应该回复,不管对方是否收到),验证和回复先后顺序无所谓;也不会因为从当前map中发现对方异常而不回复(有可能是自身问题导致map有误?,而实际上对方是正常的);后续验证主要对epoch 进行简单的同步,自身的epoch 比较大则会发送给对方
从自身的osdmap验证对方的存在,不存在则会发送YOU_DIED 类型的心跳包,告知对方已经died(多重验证)
问题: 有无复现回复丢包的手段(比如发送不成功),以及内部子系统 出现问题无法回复的现象?
模拟丢包率:osd_debug_drop_ping_probability 可以是设定丢包概率,也就是在检测内部子系统健康之前,做一个判断,实际就是跳过回复心跳流程从而实现丢包的场景
模拟内部子系统不健康场景: heartbeat_inject_failure 该参数设定是接下来时间内都是不健康的,实际就是验证健康之前会对这数值做比较
心跳回复(PING_REPLY)
回复心跳包中带有该心跳发起的时间戳,在本地(osd内存)可以通过该时间戳来找到对应的心跳记录(每一次的心跳收发时间都会在本机有记录)从而更新收到心跳回复的时间(这是判断超时的关键),心跳回复的来源可能来自前端或者后端,更新接收时间前有对来源做区分;正常情况下,前后端的回复都收到后,会统计这次心跳收发的时长,并且也会记录到本地(方面后续统计收发的平均时长);
在做完心跳接收时间的更新,会对当前收到心跳回复做一次超时检验(收到回复的时间和超时期限时间比较),这里只对非超时(正常)的回复做处理: 在检测超时回复的逻辑中,都会将超时的report 保存到一个 map中,我们这里暂且将这个map 称为failure_queue;如果回复是正常的,则会尝试在failure_queue找到以往的超时report(通过回复方的osd id找)并清楚掉;
为什么这样处理呢? 给mon上报消息是有时间间隔的,假如osd.1的回复超时了被加入到report中,而在最新的心跳中osd.1的回复是正常的,如果此时还没有上报,会从failure_queue清楚掉osd.1的超时记录,这样可以使report更为准确(省资源);
问题: 本地记录的心跳记录会不会重置的?
会,在一个完整的心跳流程(即心跳发送了有回复)结束后,起始到现在的记录都会清除掉,在这个期间的心跳记录不管是否有完成了,都会清楚掉,因为最新的已经完成了,所以不用考虑以往的
osd 心跳的之间通信有专门的模块 message 来负责连接通信,当连接出问题时候,会重置message模块,此时会将心跳记录重新清楚掉
问题: 对于心跳往返平均时间从哪里可以看到?取样的频率可以设定吗?
- amidn socke 提供了相应接口可以查看( dump_osd_network),对于取样频率通过参数 debug_heartbeat_testing_span 可以调整(这值是采样得间隔时间,默认为0)
问题: 为什么需要最后做超时验证呢?
使 failure_queue的存放的failure report更加准确
问题: failure_queue 和 failure_pending 区别
failure_queue 里保存了报错的osd,failure_pending 保存的是已经上报mon的osd(防止重复上报);假如 failure_queue里面有osd.1的report,此时会验证failure_pending 里面有无osd.1 的记录,没有则会上报,并将osd保存到failure_pending中,若是failure_pending 有纪录,则不会上报,这样做可以避免重复上报;
failure_queue 是上报一次就清除一个(不管是否上报成功)
收到消息是 YOU_DIED
对方在osdmap 中找不到我,当收到这种类型的信息是需要主动从mon中获取最近osdmap
mon处理 failed report
处理 report 分为两步
预处理
- 验证report 来源(是谁上报的)
- 从 osdmap 中验证目标osd是否已经 dowm
- 从 osdmap 中校对 目标osd的IP地址(report 中有包含)
- 从 集群osd up状态来判定,默认up状态的osd 所占集群总osd的比例为 0.3
预更新
验证 目标osd状态(期望是 up) 和 地址(通过osdmap中的记录的地址做匹配)
通过report 中osd 超时时间,反推出 osd异常的时间点(读去这个 report 的时间减去 osd超时时间,虽然不能很精确的定位到osd异常时间点,但可以保证是在这个时间段),根据这个时间点最终计算出 超时时间

mon 需要两个以上来自不同故障域osd上报,才能判定;如果osd处于同一个故障域,假如说是 rack级,若机柜出问题了则可能导致处于统一给故障域的osd与外界隔离(比如网络问题),此时上报可能会有误,为了校对这种情况,mon决策时会遍历每一条failure report ,将来自同一个故障域的当作一个report failure处理,这里故障域粒度可以由 mon_osd_reporter_subtree_level 指定;这种情况也不是百分百准确,还需要校对超时时间
对于超时时间也需要进行校对;每个osd down的时间都有记录,遍历 failure report时, 根据发送report的osd上一次down和现在的时间差来校对(我认为这样做是 弥补 故障域的误判)
问题: 为什么时间超时时间进行 “校对”?
有一种情况: 当mon通过 failure report 将有问题的osd 置为down之后,过了一会 该osd又正常了(反复这样就不乐观了),可能这个osd并不是真的有问题,可能这个o sd就是慢半拍,如果可以稍微缩放一下容忍时间,可能就不会出现这种现象;但又不能单独为这个osd调节整体的容忍时间;为了“缓解”这个问题,通过每一次 osd down 到恢复正常的时间间隔推算出 “laggy” 的概率,通过这个系数来缩放 容忍时间;
// mon -> 方敏
其他问题汇总:
问题: 其他辅助检测方式
osd 周期性的(300s)发送信息给mon保活,需要构建 MOSDBeacon 类并发送给mon,mon会对这类信息做验证(通过osdmap验证),如果发现该osd是异常的,也会尝试 通知改osd自身处于异常状态
osd 主动关闭时,会构造 MOSDMarkMeDown 类信息发给mon,mon那边收到后 会验证消息来源后,将改osd置为down
osd 周期性检测 osd使用容量状态(FULL,BACKFILLFULL,NEARFULL),并将这个状态发送给mon
问题: 心跳包中为什么要携带 epoch
问