Last updated on a year ago
osd 心跳是什么,有什么功能作用 心跳是什么? 心跳是一种用于故障检测的手段(简单的说就是发个数据包给你,通过有没有回复来判断你的状态)。在分布式系统中有很多节点,节点数量多了,各种异常就会经常发生,如:宕机、磁盘损坏 、网络故障等,通过心跳这种机制可以快速有效的定位集群 中的错误节点,并做及时的处理保证集群正常服务。
osd 心跳
osd之间检测
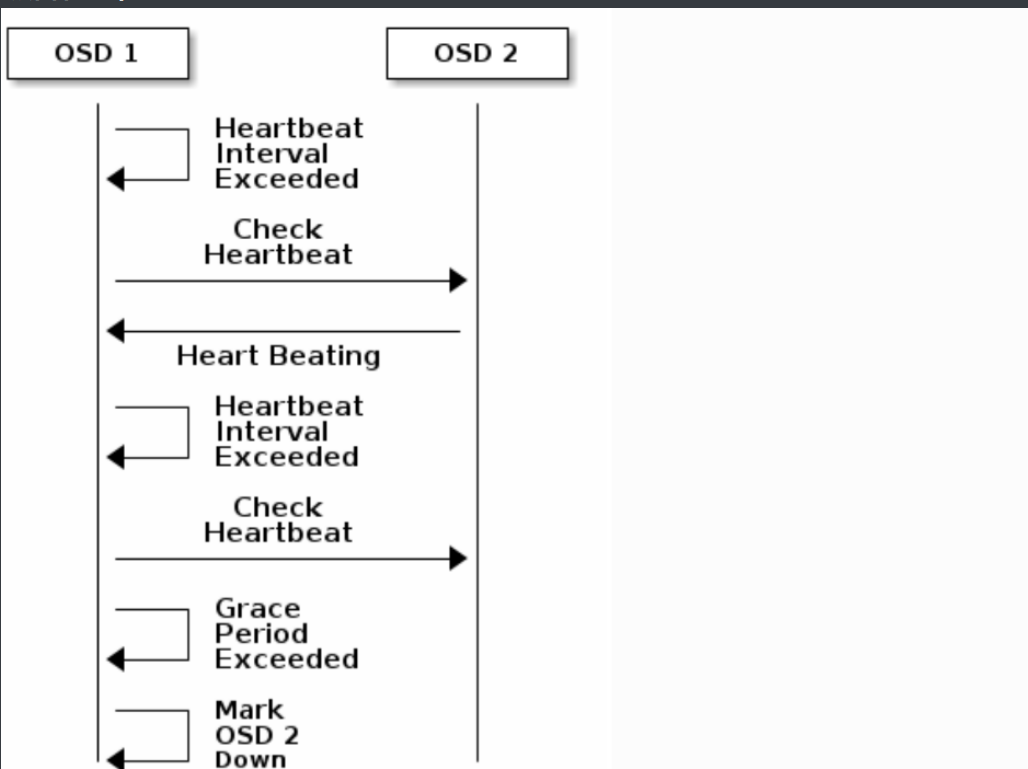
每个 Ceph OSD 守护进程以小于每 6 秒的随机间隔时间检查其他 Ceph OSD 守护进程的心跳(可以理解为:定期去敲邻居的门)
如果一个相邻的Ceph OSD Daemon在20秒的宽限期内没有显示心跳,Ceph OSD Daemon可能会认为相邻的Ceph OSD Daemon是 dowm状态的,并将其报告给Ceph Monitor(可以理解为:敲了那么长时间的门都没来开门,就报警了)
一个osd 无法和配置文件中的osd 达成 peer 关系,则这个osd 每 30 秒 ping 一次mon 以获取集群的osdmap
如果集群只有一个osd,则 osd每隔 一个 osd_mon_heartbeat_interval 的时间向 mon 获取新的 osdmap
osd和mon之间 此外 osd除了有检测osd故障的职责,还需要向mon汇报自身的状况
触发汇报的情况有以下几种:
那些场景需要用到 查看 mon的日志,看丢失的心跳包:
调整osd心跳 的参数:
基本使用(参数配置) osd心跳是集群正常工作的基石,osd的心跳的使用一般都是通过调节参数来到性能上的平衡,以下是 osd心跳机制的 参数,可以用 ceph daemon 命令设置
这里补充比较重要的参数(修改可以在 使用adminsocket 在线修改参数,当然也可以在 ceph.conf 中修改添加参数后重启 )
osd_mon_heartbeat_interval
osd_heartbeat_interval
osd_heartbeat_grace
mon_osd_min_down_reporters (一般为2 )
mon_osd_reporter_subtree_level
osd_heartbeat_min_peers
osd_mon_report_interval 默认 5s
osd_beacon_report_interval
mon_osd_report_timeout
osd_mon_heartbeat_stat_stale
模块组成以及实现架构 关键的数据结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct HeartbeatInfo {int peer; utime_t first_tx; utime_t last_tx; utime_t last_rx_front; utime_t last_rx_back; epoch_t epoch; static constexpr int HEARTBEAT_MAX_CONN = 2 ;utime_t , pair<utime_t , int >> ping_history;int ,HeartbeatInfo> heartbeat_peers;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct HeartbeatDispatcher : public Dispatcher {explicit HeartbeatDispatcher (OSD *o) : Dispatcher(o->cct), osd(o) {void ms_fast_dispatch (Message *m) override heartbeat_dispatch (m);bool ms_dispatch (Message *m) override return osd->heartbeat_dispatch (m);KeyStore *ms_get_auth1_authorizer_keystore () override {return osd->ms_get_auth1_authorizer_keystore ();
整体设计 流程 osd 如何发送和接受心跳的 public network 和 cluster network osd 直接的通信数据需要通过 ceph网络层传输 ; 一般来说 ceph集群是 内外网分离的,集群内部通信用单独cluster network,客户端外部和集群通信也是单独用 public network (可以理解为用两张网卡)
osd之间心跳通信使用了 四个message对象 (ceph中 用于通信的类在 osd 初始化时会创建,可以理解为一个专门负责派送某一种类型的快递员)用于osd心跳通信,分别是
ms_hb_front_client : 用于向其他 osd 发送心跳
ms_hb_back_client : 用于向其他 osd 发送心跳
ms_hb_back_server : 用于接受他 osd 发送心跳
ms_hb_front_server : 用于接收他 osd 发送心跳
front 用的是public network,用于检测客户端网络连接问题,back 用的是 cluster network。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 # ceph_osd.ccint main (int argc, const char **argv) create (g_ceph_context, cluster_msg_type,entity_name_t ::OSD (whoami), "hb_back_client" ,getpid (), Messenger::HEARTBEAT);create (g_ceph_context, public_msg_type,entity_name_t ::OSD (whoami), "hb_front_client" ,getpid (), Messenger::HEARTBEAT);create (g_ceph_context, cluster_msg_type,entity_name_t ::OSD (whoami), "hb_back_server" ,getpid (), Messenger::HEARTBEAT);create (g_ceph_context, public_msg_type,entity_name_t ::OSD (whoami), "hb_front_server" ,getpid (), Messenger::HEARTBEAT);new OSD (g_ceph_context,start ();start ();start ();start ();
ms_hbclient <-> ms_hb_back_server ms_hbclient <-> ms_hb_front_server。
发送数据
osd 专门开了一个线程用来 发送心跳,遍历 heartbeat_peers ,逐个发送心跳包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 struct T_Heartbeat : public Thread {explicit T_Heartbeat (OSD *o) : osd(o) {void *entry () override heartbeat_entry ();return 0 ;int OSD::init () create ("osd_srv_heartbt" );void OSD::heartbeat_entry () std::lock_guard l (heartbeat_lock) ;if (is_stopping ())return ;while (!heartbeat_stop) {heartbeat ();double wait;if (cct->_conf.get_val <bool >("debug_disable_randomized_ping" )) {float )cct->_conf->osd_heartbeat_interval;else {.5 + ((float )(rand () % 10 )/10.0 ) * (float )cct->_conf->osd_heartbeat_interval;utime_t w;set_from_double (wait);dout (30 ) << "heartbeat_entry sleeping for " << wait << dendl;WaitInterval (heartbeat_lock, w);if (is_stopping ())return ;dout (30 ) << "heartbeat_entry woke up" << dendl;
发送 heartbeat 过程都在 heartbeat(); 中 ,这里分析下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 void OSD::heartbeat () ceph_assert (heartbeat_lock.is_locked_by_me ());dout (30 ) << "heartbeat" << dendl;double loadavgs[1 ];int hb_interval = cct->_conf->osd_heartbeat_interval;int n_samples = 86400 ;if (hb_interval > 1 ) {if (n_samples < 1 )1 ;"send times : " << n_samples << std::endl;if (getloadavg (loadavgs, 1 ) == 1 ) {0 ] << std::endl;set (l_osd_loadavg, 100 * loadavgs[0 ]);1 ) + loadavgs[0 ]) / n_samples;dout (1 ) << "heartbeat: daily_loadavg " << daily_loadavg << dendl;dout (1 ) << "heartbeat checking stats" << dendl;int > hb_peers;for (map<int ,HeartbeatInfo>::iterator p = heartbeat_peers.begin ();end ();push_back (p->first);auto new_stat = service.set_osd_stat (hb_peers, get_num_pgs ());dout (5 ) << __func__ << " " << new_stat << dendl;ceph_assert (new_stat.statfs.total);float pratio;float ratio = service.compute_adjusted_ratio (new_stat, &pratio);"ratio : " << ratio << std::endl; check_full_status (ratio, pratio);utime_t now = ceph_clock_now ();utime_t deadline = now;"now " << now << std::endl;"deadline " << deadline << std::endl;for (map<int ,HeartbeatInfo>::iterator i = heartbeat_peers.begin ();end ();int peer = i->first;if (i->second.first_tx == utime_t ())make_pair (deadline,if (i->second.hb_interval_start == utime_t ())dout (1 ) << "heartbeat sending ping to osd." << peer << dendl;send_message (new MOSDPing (monc->get_fsid (),get_osdmap_epoch (),if (i->second.con_front)send_message (new MOSDPing (monc->get_fsid (),get_osdmap_epoch (),set (l_osd_hb_to, heartbeat_peers.size ());dout (30 ) << "heartbeat lonely?" << dendl;if (heartbeat_peers.empty ()) {if (now - last_mon_heartbeat > cct->_conf->osd_mon_heartbeat_interval && is_active ()) {dout (1 ) << "i have no heartbeat peers; checking mon for new map" << dendl;osdmap_subscribe (get_osdmap_epoch () + 1 , false );dout (30 ) << "heartbeat done" << dendl;
更新 heartbeat_peers osd 发送心跳包给peer osd,peer OSD的选择并不是集群中的全部osd,peer OSD如果选择其他所有结点,则会增加集群负载影响系统性能。peer OSD的选择是通过maybe_update_heartbeat_peers函数经行更新 heartbeat_peers;有以下三种情况会更新 heartbeat_peers:
pg创建的时候,参见handle_pg_create;
osdmap变更时,参见handle_osd_map;
tick定时器会周期性的检测.
osd 每次发送心跳的时候都需要遍历 heartbeat_peers, heartbeat_peers的 是个map,其 key 为osd的id,value是 HeartbeatInfo 结构体
map<int,HeartbeatInfo> heartbeat_peers; ///< map of osd id to HeartbeatInfo
tick定时器会周期性的检测. ceph 使用了一个定时器来更新 heartbeat_peers
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 double OSD::get_tick_interval () const constexpr auto delta = 0.05 ;return (OSD_TICK_INTERVAL *generate_random_number (1.0 - delta, 1.0 + delta));add_event_after (get_tick_interval (),new C_Tick (this ));class OSD ::C_Tick : public Context {public :explicit C_Tick (OSD *o) : osd(o) {void finish (int r) override tick ();
osd->tick()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void OSD::tick () ceph_assert (osd_lock.is_locked ());dout (10 ) << "tick" << dendl;if (is_active () || is_waiting_for_healthy ()) {maybe_update_heartbeat_peers ();if (is_waiting_for_healthy ()) {start_boot ();if (is_waiting_for_healthy () || is_booting ()) {std::lock_guard l (heartbeat_lock) ;utime_t now = ceph_clock_now ();if (now - last_mon_heartbeat > cct->_conf->osd_mon_heartbeat_interval) {dout (1 ) << __func__ << " checking mon for new map" << dendl;osdmap_subscribe (get_osdmap_epoch () + 1 , false );do_waiters ();add_event_after (get_tick_interval (), new C_Tick (this ));
OSD::tick 中 更新 heartbeat_peers 的关键函数是 maybe_update_heartbeat_peers() 这里简要分析下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 void OSD::maybe_update_heartbeat_peers () ceph_assert (osd_lock.is_locked ());if (is_waiting_for_healthy () || is_active ()) {utime_t now = ceph_clock_now ();if (last_heartbeat_resample == utime_t ()) {heartbeat_set_peers_need_update ();else if (!heartbeat_peers_need_update ()) {utime_t dur = now - last_heartbeat_resample;if (dur > cct->_conf->osd_heartbeat_grace) {dout (10 ) << "maybe_update_heartbeat_peers forcing update after " << dur << " seconds" << dendl;heartbeat_set_peers_need_update ();reset_heartbeat_peers (is_waiting_for_healthy ());if (is_active ()) {for (auto & pg : pgs) {with_heartbeat_peers ([&](int peer) {if (get_osdmap ()->is_up (peer)) {int > want, extras;const int next = get_osdmap ()->get_next_up_osd_after (whoami);if (next >= 0 )insert (next);int prev = get_osdmap ()->get_previous_up_osd_before (whoami);if (prev >= 0 && prev != next)insert (prev);auto min_down = cct->_conf.get_val <uint64_t >("mon_osd_min_down_reporters" );auto subtree = cct->_conf.get_val <string>("mon_osd_reporter_subtree_level" );get_osdmap ()->get_random_up_osds_by_subtree (for (set<int >::iterator p = want.begin (); p != want.end (); ++p) {dout (10 ) << " adding neighbor peer osd." << *p << dendl;insert (*p);int ,HeartbeatInfo>::iterator p = heartbeat_peers.begin ();while (p != heartbeat_peers.end ()) {if (!get_osdmap ()->is_up (p->first)) {int o = p->first;continue ;if (p->second.epoch < get_osdmap_epoch ()) {insert (p->first);for (int n = next; n >= 0 ; ) {if ((int )heartbeat_peers.size () >= cct->_conf->osd_heartbeat_min_peers)break ;if (!extras.count (n) && !want.count (n) && n != whoami) {dout (10 ) << " adding random peer osd." << n << dendl;insert (n);get_osdmap ()->get_next_up_osd_after (n);if (n == next)break ; for (set<int >::iterator p = extras.begin ();int )heartbeat_peers.size () > cct->_conf->osd_heartbeat_min_peers && p != extras.end ();if (want.count (*p))continue ;dout (10 ) << "maybe_update_heartbeat_peers " << heartbeat_peers.size () << " peers, extras " << extras << dendl;
pg创建的时候 在 函数 handle_pg_create 里最后也调用了 maybe_update_heartbeat_peers();
1 2 3 4 5 6 7 8 9 10 void OSD::handle_pg_create (OpRequestRef op) const MOSDPGCreate *m = static_cast <const MOSDPGCreate*>(op->get_req ());ceph_assert (m->get_type () == MSG_OSD_PG_CREATE);dout (10 ) << "handle_pg_create " << *m << dendl;maybe_update_heartbeat_peers ();
osdmap 变更时候 1 2 3 4 5 6 7 void OSD::handle_osd_map (MOSDMap *m) if (is_active () || is_waiting_for_healthy ())maybe_update_heartbeat_peers ();
接收数据 在 osd初始化时,创建四个关于心跳的 message,(上文有提到), Message 类中 处理消息的方法 handle 会注册到分发中心
1 2 3 4 5 6 7 8 9 10 11 12 int OSD::init () add_dispatcher_head (&heartbeat_dispatcher);add_dispatcher_head (&heartbeat_dispatcher);add_dispatcher_head (&heartbeat_dispatcher);add_dispatcher_head (&heartbeat_dispatcher);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 bool OSD::heartbeat_dispatch (Message *m) dout (30 ) << "heartbeat_dispatch " << m << dendl;switch (m->get_type ()) {case CEPH_MSG_PING:dout (10 ) << "ping from " << m->get_source_inst () << dendl;put ();break ;case MSG_OSD_PING:handle_osd_ping (static_cast <MOSDPing*>(m));break ;default :dout (0 ) << "dropping unexpected message " << *m << " from " << m->get_source_inst () << dendl;put ();return true ;
这里分析下 当 osd 收到心跳包后 handle_osd_ping是怎么处理的
处理心跳通知 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 case MOSDPing::PING:if (!cct->get_heartbeat_map ()->is_healthy ()) {dout (10 ) << "internal heartbeat not healthy, dropping ping request" << dendl;break ;new MOSDPing (monc->get_fsid (),get_epoch (),get_connection ()->send_message (r);if (curmap->is_up (from)) {note_peer_epoch (from, m->map_epoch);if (is_active ()) {get_con_osd_cluster (from, curmap->get_epoch ());if (con) {share_map_peer (from, con.get ());else if (!curmap->exists (from) ||get_down_at (from) > m->map_epoch) {new MOSDPing (monc->get_fsid (),get_epoch (),get_connection ()->send_message (r);
处理心跳回复 处理函数太长了,大概看了下,主要功能是 根据时间戳更新 ping_history,更新peer对应的 HeartbeatInfo,以及 osd状态,这里没有心跳超时的检测,有一个定时任务专门负责
心跳超时检测 和上报消息 心跳超时检测 在 OSD::init()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int OSD::init () add_event_after (get_tick_interval (),new C_Tick (this ));std::lock_guard l (tick_timer_lock) ;add_event_after (get_tick_interval (),new C_Tick_WithoutOSDLock (this ));class OSD ::C_Tick_WithoutOSDLock : public Context {public :explicit C_Tick_WithoutOSDLock (OSD *o) : osd(o) {void finish (int r) override tick_without_osd_lock ();
这里详细介绍下 tick_without_osd_lock
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 void OSD::tick_without_osd_lock () if (is_active () || is_waiting_for_healthy ()) {Lock ();heartbeat_check ();Unlock ();get_read ();std::lock_guard l (mon_report_lock) ;utime_t now = ceph_clock_now ();if (service.need_fullness_update () ||send_full_update ();send_failures ();put_read ();epoch_t max_waiting_epoch = 0 ;for (auto s : shards) {max (max_waiting_epoch,get_max_waiting_epoch ());if (max_waiting_epoch > get_osdmap ()->get_epoch ()) {dout (20 ) << __func__ << " max_waiting_epoch " << max_waiting_epoch", requesting new map" << dendl;osdmap_subscribe (superblock.newest_map + 1 , false );if (is_active ()) {const auto now = ceph::coarse_mono_clock::now ();const auto elapsed = now - last_sent_beacon;if (chrono::duration_cast <chrono::seconds>(elapsed).count () >true ;if (need_send_beacon) {send_beacon (now);add_event_after (get_tick_interval (),new C_Tick_WithoutOSDLock (this ));
heartbeat_check 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 void OSD::heartbeat_check () ceph_assert (heartbeat_lock.is_locked ());utime_t now = ceph_clock_now ();for (map<int ,HeartbeatInfo>::iterator p = heartbeat_peers.begin ();end ();if (p->second.first_tx == utime_t ()) {dout (30 ) << "heartbeat_check we haven't sent ping to osd." << p->first" yet, skipping" << dendl;continue ;if (p->second.is_unhealthy (now)) {utime_t oldest_deadline = p->second.ping_history.begin ()->second.first;if (p->second.last_rx_back == utime_t () ||utime_t ()) {else {min (p->second.last_rx_back, p->second.last_rx_front);
mon 如何处理上报信息的
和osd接受心跳消息一样,在mon中 也是有一个dispatch 来处理信息,并且也是根据消息类型来处理
最终会调用 paxos_service[PAXOS_OSDMAP]->dispatch(op); paxos_service 在 mon初始化时候就已经构造好了,可以看到处理reset重新指向了OSDMonitor的类,所以说处理报错消息是由OSDMonitor类的函数处理的;
看看 paxos_service[PAXOS_OSDMAP]->dispatch(op) 是怎么处理的
预处理 preprocess_query
更行状态 prepare_update
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 bool PaxosService::dispatch (MonOpRequestRef op) if (preprocess_query (op)) return true ; if (!prepare_update (op)) {return true ;if (need_immediate_propose) {dout (10 ) << __func__ << " forced immediate propose" << dendl;false ;propose_pending ();return true ;
先说下 preprocess_query
preprocess_query 函数中处理了很多种类型消息,其中 MSG_OSD_FAILURE 对应的处理函数是 preprocess_failure
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 bool OSDMonitor::preprocess_query (MonOpRequestRef op) mark_osdmon_event (__func__);get_req ();switch (m->get_type ()) {case MSG_OSD_MARK_ME_DOWN:return preprocess_mark_me_down (op);case MSG_OSD_FULL:return preprocess_full (op);case MSG_OSD_FAILURE:return preprocess_failure (op);default :ceph_abort ();return true ;
最终 调用 preprocess_failure ,这里多次验证这个消息是否准确的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 bool OSDMonitor::preprocess_failure (MonOpRequestRef op) mark_osdmon_event (__func__);static_cast <MOSDFailure*>(op->get_req ());int badboy = m->get_target_osd ();if (check_source (op, m->fsid))goto didit;dout (5 ) << "osd test " << badboy << dendl;if (m->get_orig_source ().is_osd ()) {int from = m->get_orig_source ().num ();if (!osdmap.exists (from) ||get_addrs (from).legacy_equals (m->get_orig_source_addrs ()) ||is_down (from) && m->if_osd_failed())) {dout (5 ) << "preprocess_failure from dead osd." << from", ignoring" << dendl;send_incremental (op, m->get_epoch ()+1 );goto didit;if (osdmap.is_down (badboy)) {dout (5 ) << "preprocess_failure dne(/dup?): osd." << m->get_target_osd ()" " << m->get_target_addrs ()", from " << m->get_orig_source () << dendl;if (m->get_epoch () < osdmap.get_epoch ())send_incremental (op, m->get_epoch ()+1 );goto didit;if (osdmap.get_addrs (badboy) != m->get_target_addrs ()) {dout (5 ) << "preprocess_failure wrong osd: report osd." << m->get_target_osd ()" " << m->get_target_addrs ()" != map's " << osdmap.get_addrs (badboy)", from " << m->get_orig_source () << dendl;if (m->get_epoch () < osdmap.get_epoch ())send_incremental (op, m->get_epoch ()+1 );goto didit;if (osdmap.is_down (badboy) ||get_up_from (badboy) > m->get_epoch ()) {dout (5 ) << "preprocess_failure dup/old: osd." << m->get_target_osd ()" " << m->get_target_addrs ()", from " << m->get_orig_source () << dendl;if (m->get_epoch () < osdmap.get_epoch ())send_incremental (op, m->get_epoch ()+1 );goto didit;if (!can_mark_down (badboy)) {dout (5 ) << "preprocess_failure ignoring report of osd." get_target_osd () << " " << m->get_target_addrs ()" from " << m->get_orig_source () << dendl;goto didit;return false ;no_reply (op);return true ;
验证之后执行 prepare_update,和preprocess_query 一样也是通过消息类型来执行对应的处理函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 bool OSDMonitor::prepare_update (MonOpRequestRef op) 7 ) << "prepare_update " << *m << " from " << m->get_orig_source_inst() << dendl;switch (m->get_type()) {case MSG_OSD_FAILURE:return prepare_failure(op);return false ;
prepare_failure 函数将报告添加到 failure_info中,最后再 check_failure 执行标记osd down的错误
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 bool OSDMonitor::prepare_failure (MonOpRequestRef op) mark_osdmon_event (__func__);static_cast <MOSDFailure*>(op->get_req ());dout (1 ) << "prepare_failure osd." << m->get_target_osd ()" " << m->get_target_addrs ()" from " << m->get_orig_source ()" is reporting failure:" << m->if_osd_failed() << dendl;int target_osd = m->get_target_osd ();int reporter = m->get_orig_source ().num ();ceph_assert (osdmap.is_up (target_osd));ceph_assert (osdmap.get_addrs (target_osd) == m->get_target_addrs ());no_reply (op);if (m->if_osd_failed()) {utime_t now = ceph_clock_now ();utime_t failed_since =get_recv_stamp () - utime_t (m->failed_for, 0 );if (m->is_immediate ()) {debug () << "osd." << m->get_target_osd ()" reported immediately failed by " get_orig_source ();return true ;debug () << "osd." << m->get_target_osd () << " reported failed by " get_orig_source ();failure_info_t & fi = failure_info[target_osd];add_report (reporter, failed_since, op);if (old_op) {no_reply (old_op);return check_failure (now, target_osd, fi);else {debug () << "osd." << m->get_target_osd ()" failure report canceled by " get_orig_source ();if (failure_info.count (target_osd)) {failure_info_t & fi = failure_info[target_osd];cancel_report (reporter);if (report_op) {no_reply (report_op);if (fi.reporters.empty ()) {dout (10 ) << " removing last failure_info for osd." << target_osderase (target_osd);else {dout (10 ) << " failure_info for osd." << target_osd << " now " size () << " reporters" << dendl;else {dout (10 ) << " no failure_info for osd." << target_osd << dendl;return false ;
check_failure 函数并没有直接标记osd 为down,而是通过各种条件来调节 osd 失败的时间,然后再和 实际的osd_heartbeat_grace 做比较,以及上报数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 bool OSDMonitor::check_failure (utime_t now, int target_osd, failure_info_t & fi) if (pending_inc.new_state.count (target_osd) &&dout (10 ) << " already pending failure" << dendl;return true ;auto reporter_subtree_level = g_conf ().get_val <string>("mon_osd_reporter_subtree_level" );utime_t orig_grace (g_conf()->osd_heartbeat_grace, 0 ) utime_t max_failed_since = fi.get_failed_since ();utime_t failed_for = now - max_failed_since;utime_t grace = orig_grace;double my_grace = 0 , peer_grace = 0 ;double decay_k = 0 ;if (g_conf ()->mon_osd_adjust_heartbeat_grace) {double halflife = (double )g_conf ()->mon_osd_laggy_halflife;log (.5 ) / halflife;const osd_xinfo_t & xi = osdmap.get_xinfo (target_osd);double decay = exp ((double )failed_for * decay_k);dout (1 ) << " halflife " << halflife << " decay_k " << decay_k" failed_for " << failed_for << " decay " << decay << dendl;double )xi.laggy_interval * xi.laggy_probability;ceph_assert (fi.reporters.size ());for (auto p = fi.reporters.begin (); p != fi.reporters.end ();) {if (osdmap.exists (p->first)) {auto reporter_loc = osdmap.crush->get_full_location (p->first);if (auto iter = reporter_loc.find (reporter_subtree_level);end ()) {insert ("osd." + to_string (p->first));dout (1 ) <<"reporters_by_subtree, reporter_subtree_level:" <<reporter_subtree_level " vname:" << "osd." + to_string (p->first) << dendl;else {get_phy_name (iter->second);dout (1 ) <<"reporters_by_subtree, reporter_subtree_level:" <<reporter_subtree_level " vname:" << iter->second << " pname:" << name << dendl;insert (name);if (g_conf ()->mon_osd_adjust_heartbeat_grace) {const osd_xinfo_t & xi = osdmap.get_xinfo (p->first);utime_t elapsed = now - xi.down_stamp;double decay = exp ((double )elapsed * decay_k);double )xi.laggy_interval * xi.laggy_probability;else {cancel_report (p->first);;erase (p);if (g_conf ()->mon_osd_adjust_heartbeat_grace) {double )fi.reporters.size ();dout (10 ) << " osd." << target_osd << " has " size () << " reporters, " " grace (" << orig_grace << " + " << my_grace" + " << peer_grace << "), max_failed_since " << max_failed_sinceif (failed_for >= grace &&size () >= g_conf ().get_val <uint64_t >("mon_osd_min_down_reporters" )) {dout (1 ) << " we have enough reporters to mark osd." << target_osd" down" << dendl;info () << "osd." << target_osd << " failed (" get_full_location_ordered_string (") (" int )reporters_by_subtree.size ()" reporters from different " " after " " >= grace " << grace << ")" ;return true ;return false ;
让后执行bool PaxosService::dispatch(MonOpRequestRef op)
OSDMonitor::preprocess_query(MonOpRequestRef op)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 bool OSDMonitor::preprocess_query (MonOpRequestRef op) mark_osdmon_event (__func__);get_req ();dout (10 ) << "preprocess_query " << *m << " from " << m->get_orig_source_inst () << dendl;switch (m->get_type ()) {case MSG_OSD_FAILURE:return preprocess_failure (op);default :ceph_abort ();return true ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 bool OSDMonitor::preprocess_failure (MonOpRequestRef op) mark_osdmon_event (__func__);static_cast <MOSDFailure*>(op->get_req ());int badboy = m->get_target_osd ();if (check_source (op, m->fsid))goto didit;if (m->get_orig_source ().is_osd ()) {int from = m->get_orig_source ().num ();if (!osdmap.exists (from) ||get_addrs (from).legacy_equals (m->get_orig_source_addrs ()) ||is_down (from) && m->if_osd_failed())) {dout (5 ) << "preprocess_failure from dead osd." << from", ignoring" << dendl;send_incremental (op, m->get_epoch ()+1 );goto didit;if (osdmap.is_down (badboy)) {dout (5 ) << "preprocess_failure dne(/dup?): osd." << m->get_target_osd ()" " << m->get_target_addrs ()", from " << m->get_orig_source () << dendl;if (m->get_epoch () < osdmap.get_epoch ())send_incremental (op, m->get_epoch ()+1 );goto didit;if (osdmap.get_addrs (badboy) != m->get_target_addrs ()) {dout (5 ) << "preprocess_failure wrong osd: report osd." << m->get_target_osd ()" " << m->get_target_addrs ()" != map's " << osdmap.get_addrs (badboy)", from " << m->get_orig_source () << dendl;if (m->get_epoch () < osdmap.get_epoch ())send_incremental (op, m->get_epoch ()+1 );goto didit;if (osdmap.is_down (badboy) ||get_up_from (badboy) > m->get_epoch ()) {dout (5 ) << "preprocess_failure dup/old: osd." << m->get_target_osd ()" " << m->get_target_addrs ()", from " << m->get_orig_source () << dendl;if (m->get_epoch () < osdmap.get_epoch ())send_incremental (op, m->get_epoch ()+1 );goto didit;if (!can_mark_down (badboy)) {dout (5 ) << "preprocess_failure ignoring report of osd." get_target_osd () << " " << m->get_target_addrs ()" from " << m->get_orig_source () << dendl;goto didit;dout (10 ) << "preprocess_failure new: osd." << m->get_target_osd ()" " << m->get_target_addrs ()", from " << m->get_orig_source () << dendl;return false ;no_reply (op);return true ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 bool OSDMonitor::check_failure (utime_t now, int target_osd, failure_info_t & fi) if (pending_inc.new_state.count (target_osd) &&dout (10 ) << " already pending failure" << dendl;return true ;auto reporter_subtree_level = g_conf ().get_val <string>("mon_osd_reporter_subtree_level" );utime_t orig_grace (g_conf()->osd_heartbeat_grace, 0 ) utime_t max_failed_since = fi.get_failed_since ();utime_t failed_for = now - max_failed_since;utime_t grace = orig_grace;double my_grace = 0 , peer_grace = 0 ;double decay_k = 0 ;if (g_conf ()->mon_osd_adjust_heartbeat_grace) {double halflife = (double )g_conf ()->mon_osd_laggy_halflife;log (.5 ) / halflife;const osd_xinfo_t & xi = osdmap.get_xinfo (target_osd);double decay = exp ((double )failed_for * decay_k);dout (1 ) << " halflife " << halflife << " decay_k " << decay_k" failed_for " << failed_for << " decay " << decay << dendl;double )xi.laggy_interval * xi.laggy_probability;for (auto p = fi.reporters.begin (); p != fi.reporters.end ();) {if (osdmap.exists (p->first)) {auto reporter_loc = osdmap.crush->get_full_location (p->first);if (auto iter = reporter_loc.find (reporter_subtree_level);end ()) {insert ("osd." + to_string (p->first));else {get_phy_name (iter->second);insert (name);if (g_conf ()->mon_osd_adjust_heartbeat_grace) {const osd_xinfo_t & xi = osdmap.get_xinfo (p->first);utime_t elapsed = now - xi.down_stamp;double decay = exp ((double )elapsed * decay_k);double )xi.laggy_interval * xi.laggy_probability;else {cancel_report (p->first);;erase (p);if (g_conf ()->mon_osd_adjust_heartbeat_grace) {double )fi.reporters.size ();if (failed_for >= grace &&size () >= g_conf ().get_val <uint64_t >("mon_osd_min_down_reporters" )) {return true ;return false ;
一类是同个PG下的OSD节点之间
另一类是OSD的左右两个相邻的节点,
可以用于节点间检测对方是否故障,以便及时发现故障节点后进入相应的故障处理流程。
每个OSD节点(守护进程)会监听public、cluster、front和back四个端口
public端口:监听来自Monitor和Client的连接。
cluster端口:监听来自OSD Peer的连接(同一个集群内的osd)。
front端口:供客户端连接集群使用的网卡, 这里临时给集群内部之间进行心跳。
back端口:供客集群内部使用的网卡。集群内部之间进行心跳。
每个 Ceph OSD 守护进程每 6 秒检查其他 Ceph OSD 守护进程的心跳。要更改心跳间隔,请在 Ceph 配置文件的 [osd] 部分下添加 osd heartbeat interval 设置,或者在运行时更改其值。
如果邻居 Ceph OSD 守护进程未在 20 秒宽限期内发送 heartbeat 数据包,Ceph OSD 守护进程可能会考虑相邻的 Ceph OSD 守护进程 停机。它将报告回 Ceph 监控器,后者将更新 Ceph 群集映射。若要更改此宽限期,可在 Ceph 配置文件的 [osd] 部分下添加 osd heartbeat 宽限期,或者在运行时设置其值。
osd 之间心跳机制:osd之间会互相通信,通信间隔时间在随机 6s以内;如果在20s后没有收到osd没有收到相邻的osd心跳,会认为相邻的osd已经 dowm,并报告给 mon;
osd和mon之间的心跳机制:
向mon 上报 osd down信息,mon判断机制是收到两个以上某个osd dowm的信息
上报 osd 状态,变更信息,不管osd 有没有变更信息,每个120s都要上报一次
当 获取不到 邻居osd信息时,上报给mon获取新的 osdmap
\
 ·
·




















