一致性哈希的简单理解
Last updated on a year ago
什么是一致性哈希
一致性hash算法,是麻省理工学院1997年提出的一种算法,目前主要应用于分布式缓存当中。
一致性hash算法可以有效地解决分布式存储结构下动态增加和删除节点所带来的问题。
传统hash
假如现在有三台服务器用作图片缓存,如何使用大量的图片均衡的分布在服务器上呢,如果有30万张图片,最理想的是每个服务器都负载10万张图片;使用传统hash可以对文件名进行hash(假设文件名字都不相同),得到的结果按服务器个数取模,这样做可以尽可能做到均衡;但是这有个弊端,就是服务器动态增删的事,会产生很大问题;现在有三台服务器 node1 ,node2,node3;其中node1故障,那么现在要改变映射(理论上后台会重新构建),这一时刻,命中node1的缓存是不可以使用了,需要重新hash,同理增加一台服务器也是如此,因为是对服务器数量取模,前的hash映射都会失效,无法动态调整,此时也需要重新取模,会涉及全部数据;

一致性hash
而一致性hash在普通hash功能之上,解决动态增加和删除节点带来的问题(牵一发而动全身)
实现原理
一致性哈希算法通过一个叫作一致性哈希环的数据结构实现。这个环的起点是 0,终点是 2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是 [0, 2^32-1]
第一步: 固定好节点位置,也是hash取模,可以节点ip或者节点名称取模,即 hash(ip)% 2^32 - 1,既可以固定好节点位置;
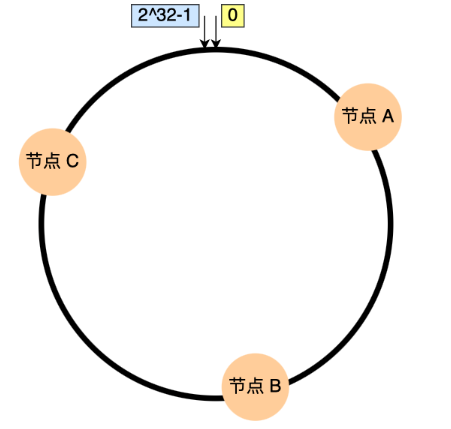
第二部: 接下来和普通hash一样,hash的值对2^32 - 1取模,找哈希环的位置然后顺时针寻找节点,找到的第一个节点则就是要存放数据的节点如下图, key-1 找到节点A,key-2找到节点B以此类推….

如果增加一个节点,并不会影响全局,只会影响局部的映射,如增加了节点D,影响的只有key-2,其他的key不影响,删除的也是如此

有什么缺陷
但是有个问题:在第一步的时候,节点定位分布到比较集中(节点数比较少也不是不可能)如下图,节点A承载了大量的数据, 如果过节点蹦了,大量的数据会迁移到节点B,这样会导致节点B的压力增大,可能会造成雪崩效应。
解决的方法可以在第一步时候添加虚拟节点,不使用真实的节点,比如节点A可以由多个节点映射,保证节点的均衡性,如下图所示,真实的A节点用虚拟节点A-01 A-02 A-03来取代,B,C同理。